


Introduction
How do search engines work? In this module, we will cover what a search engine is, the concepts of crawling and indexing, understanding crawl budgets, and optimizing your products. Now, let’s start with a brief definition of a search engine.
Search Engines: Definition and Function
A search engine is a software program designed to help people find information online using keywords or phrases. Examples of search engines like Google, Microsoft/Bing, and Yahoo, which you can use to locate specific information on the web. These top search engines organize information about web pages in a structured format.
Now, let’s understand how search engines work when you input a particular query. We will explore the backend activities that occur within the search engine. There are three main components of a search engine: the query engine, the crawler, and the indexer.
The Fundamental Components And Basics of Search Engines
- Query Engine: Processes user queries.
- Crawler: Reads information from websites.
- Indexer: Indexes and stores crawled information.
The Process of Crawling: How Search Engines Discover Content

Crawling involves reading content on web pages and storing that information in a database. For instance, if you have a website with various types of information such as text, images, and videos, a web crawler or spider will visit your site, extract the information, and save it in a database.
The first step is finding out what pages are on the web. There’s no central list of all web pages, so Google has to keep looking for new and updated pages to add to its list of known pages. This process is called “URL discovery“. Some pages are already known because Google has visited them before. Other pages are found when Google follows a link from an existing page. For example, a main page, like a category page, links to a new blog post. Google can also find new pages when you submit a list of pages (a sitemap) for Google to crawl.
Think about your website. Consider your website. A web crawler or spider visits your site or a specific seed URL.
It then scans all the information on the internet and saves it in a database. If there are links on your webpage, the crawler follows them, visiting linked pages and extracting information. This recursive process continues.
The crawler operates based on certain policies.
Crawl Policies: How Search Engines Decide What to Index

- Selection Policy: There is a selection policy that determines. It follows policies to decide which pages to visit, which to skip, and which pages the crawler should download.
- Revisit Policy: Revisit policy entails the crawler scheduling the time when it should revisit the workspace and incorporate any changes into its database. For example, if a web crawler visits your website, reads all the information, and after a few days, you make changes to your web page, Google’s crawler will revisit your website, crawl the recommended changes, and store those changes in its database.
- Parallelization Policy: In this policy, crawlers employ multiple processes simultaneously to explore links, known as distributed crawling. Suppose this is your website A, and its link is mentioned on another website B. The crawler reads your website content on website B, finds the link, and then visits your site using that link, repeating the process with multiple sources. This is known as multiple processes and distributed crawling.
- Politeness Policy: Includes In the case of politeness, we have a term called “crawl delay.” Crawl-delay refers to the pause of a few milliseconds that Google crawlers take after downloading information from a website. This delay is implemented to ensure that the crawler waits for a short period after downloading data from the website.
Now, let’s explore how crawling works. Imagine Google as your search engine.
When someone enters a query, the web spider or crawler goes to your website, reads every web page, crawls your site, copies the information, and stores it in the database. When a user queries, the search engine retrieves and displays results from this database. This is the process of how the crawler operates.
Indexing: Storing Data for Easy Access
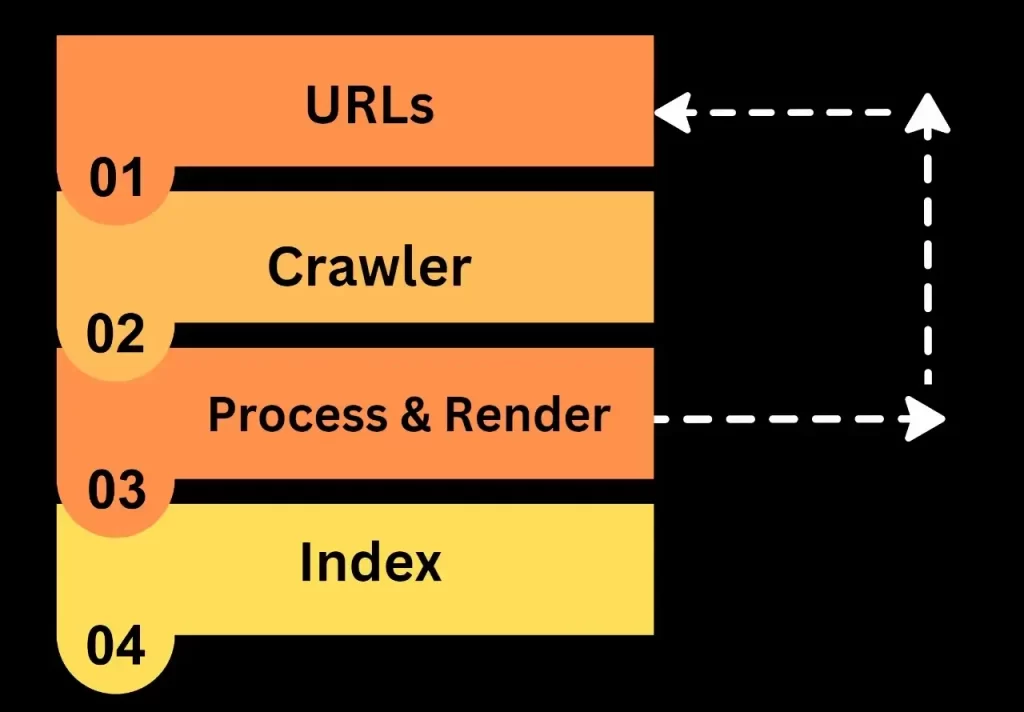
After crawling, we move to indexing. As the Google or search engine crawler gathers information from your website, the next step is indexing. Indexing is akin to creating an index for a book. If you want to find a specific topic, you can start from the search page or consult the index, locate the corresponding page number, and find the information you seek.
Okay, this is the easiest step. Simply look at your index of books and visit that particular page. The same thing happens in Google, in your search engine database where we have a lot of information. Just fetching your user’s query from that particular database is really difficult.
Therefore, search engines do indexing based on keywords. When someone searches for a particular query, the search engine checks for relevant keywords and that query or information is reflected by the user.
During the indexing process, Google checks if a page is a copy of another page on the internet or if it’s the main page also called the canonical. The canonical page is the one that might show up in search results. To choose the canonical, Google first groups together (called clustering) pages with similar content, and then picks the one that best represents the group. The other pages in the group are alternate versions that might be shown in different situations, like when a user is searching on a mobile device or is looking for a specific page in the cluster.
Google also gathers signals about the canonical page and its content, which may be used later when showing the page in search results. Some signals include the language of the page, the country it’s focused on, and how easy it is to use.
The information Google collects about the canonical page and its group may be saved in the Google index, which is a huge database stored on thousands of computers. Not every page that Google processes will be indexed, so indexing isn’t guaranteed.
Several factors contribute to creating an efficient indexing system:
- Storage information used by the indexer
- The size of the indexer
- The ability to quickly find documents containing the searched keyword.
These factors determine the efficiency and reliability of an index.
Here’s how indexing happens: a user makes a search query, and the query is passed with the help of the query engine. HTML pages or web pages of your website are the pages involved.
The indexer gets keywords from your web pages and stores them in the form of indexing in its index file or repository. When a user puts any query, the query engine looks in the index file, gets a list of matching pages, and shows the result page to the users then relevant information is visible to the users.
Types of Indexing:
There are two types of indexing: forward index and backward index.
- Forward Index: Stores all keywords in a document.
- Backward Index: Stores and converts forward indexes, grouping documents containing specific keywords.
In simple language forward index stores all keywords and the backward index makes groups of those keywords and stores them in relevant keyword groups.
How Search Engines Work: From Your Search to the Results
how does the search engine work? When a user puts any query, the search engine indexing algorithms retrieve the query from the database. The web spider crawls every single piece of information from the web page, indexes it, stores it in the database, fetches data from the index file, and sends it to the user.
This is how a search engine works. Google has a lot of search history of a user so it will show relevant results as per the public analysis.
Based on what someone searches for, the features that show up on Google’s search results page change too. For example, if you search for “car repair shops,” you’ll probably see local results, but not many images.
On the other hand, searching for “modern cars” is more likely to show you image results, but not local ones. You can check out the most common features of Google Search’s design in the Visual Element gallery.
This information will assist website owners in evaluating their search engine rankings, fostering a comprehensive understanding of how ranking factors operate. It aims to facilitate the analysis of results based on these factors.
Crawl Budget
The crawl budget is the number of times a search engine spider crawls your website in a given time. It’s essentially how often the web spider visits your website. To optimize your crawl budget and rank on the search engine’s first page, strategies need to be implemented for SEO. And you just need to know all the processes involved in SEO. These strategies include avoiding rich media files, optimizing internal and external links, using social channels, and making the website more search engine-friendly.
In this blog, we covered how search engines work. Next, we’ll delve deeper into SEO.
Recent Trends in Search Engine Technology
Recent trends in search engine technology are changing how people find information online. One big change is the use of artificial intelligence (AI) in search algorithms, with studies showing that over 70% of search queries now benefit from AI-enhanced results. AI helps search engines understand user intent better, leading to more accurate and relevant results.
Voice search is also on the rise, with approximately 55% of households expected to own smart speakers by 2025. Many people now use virtual assistants like Siri and Google Assistant, which means websites need to focus on natural language and structured data to improve visibility.
Additionally, user experience has become crucial for rankings. Research indicates that page speed can impact conversion rates, with a delay of just 1 second leading to a 7% reduction in conversions. Search engines prefer sites that load quickly and are mobile-friendly, underscoring the importance of providing a great experience for users in today’s digital landscape.
FAQs: Common Questions About Search Engines and SEO
Is there a need for search engines?
Search engines help you in searching for what you need quickly. They help you find valuable information without making you go through relevant information and pages that websites provide. They help you find a way into the vast library of information.
When do search engines remove content?
Search engines remove content when anyone violates its rules like violating someone’s privacy or defaming someone. It also removes content when there is a copyright issue and other laws as such.
What are the main components of search engines and what are their rules?
The main components of the search engine are a query engine, a crawler, and an index. The query engine processes what the user is trying to find. Crawler searches and collects the relevant information in the vast library of information. The indexer helps in indexing the content according to the relevancy and quality of the content.
How do I get my website indexed on search engines?
You can make search engines index your website by auditing any crawling errors on your website and submitting your content and website information to multiple search engines. Focus on optimizing your website content, improving site speed, and adhering to search engine guidelines.





