


Recently, Google confirmed that it only accepts four specific fields in robots.txt files in an update to its Search Central manual. The Google bots are going to ignore any unsupported fields. The purpose of this update is to help website owners and developers avoid using directives that won’t be recognized by giving them clear instructions.
Key Update
It is clear from Google’s literature that fields not specifically mentioned in robots.txt files are not supported by its crawlers. By performing this, confusion decreases and website owners are guaranteed to employ only supported directives.
“We often get asked about fields that aren’t specifically mentioned as supported, and we want to make it clear that they are not.”
It is expected that this clarification would stop websites from depending on unsupported directives that have no impact on Google’s crawling of their pages.
What Does This Mean for You?
Make sure that only fields that are supported are being used by checking your robots.txt files if you are in control of a website. Using unsupported fields, such as third-party or custom directives, will have no impact on how Google crawls your site.
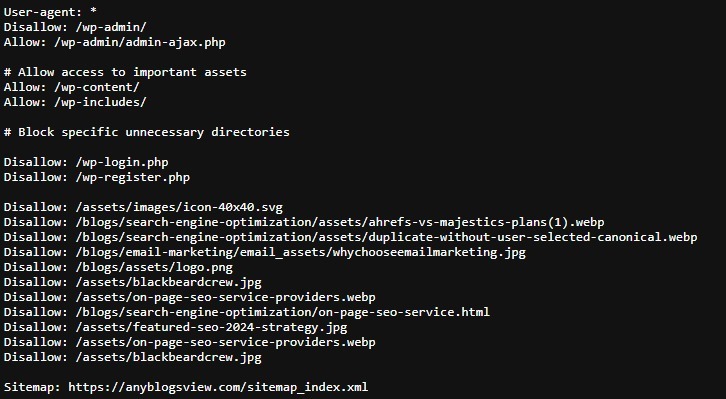
The most important fields that Google officially supports are the following:
- user-agent
- allow
- disallow
- sitemap
Any other directives, such as the commonly used “crawl-delay,” are not supported by Google, though other search engines may still recognize them. It’s also crucial to remember that Google is constantly discontinuing support for the noarchive directive.
Moving Forward
This update provides a helpful reminder to keep up with Google’s official guidelines and recommended practices. It highlights how important it is to use features that are supported and specified in robots.txt files rather than assuming that fields that are not supported might function.
Hey there, tech enthusiasts! We’ve got some important news for you. Recently, Google has rolled out several changes to its robots.txt policy. If you’re not familiar with ‘Robots.txt’, it’s essentially a set of guidelines used by websites to communicate with web crawlers and other web robots. Our recent post at ‘https://anyblogsview.com/google-changes-robots-txt-policy/’ goes in-depth regarding these changes, their impacts, and consequently, how to optimize your website to stay at the top of search results. Grab a cup of coffee and give it a read! It’s important info, especially if you’re invested in online business or web development.
Are you trying to keep your finger on the pulse of the ever-changing landscape of SEO? Then you’ve come to the right place! Our latest blog post, ‘Google Changes Robots.txt Policy’ at anyblogsview.com, is just what you need. We delve into the nitty-gritty of Google’s new policy and what it means for website owners and developers. Whether you’re looking to maximize the visibility of your content or trying to avoid serious SEO faux pas, understanding these recent alterations is a game-changer. Plus, we’re breaking it down in a way that’s straightforward and easy to understand – no techy jargon, we promise!
Are you looking to stay informed about Google’s latest updates on their robots.txt policy? Head over to ‘https://anyblogsview.com/google-changes-robots-txt-policy/’ where you’ll find everything you need to know. This site provides an easy-to-understand and up-to-date guide on how Google’s altered policy could impact your website’s SEO management. Our comprehensive blog keeps you abreast of important changes, helping align your strategies and ensuring maximum visibility for your website on Google. Don’t stay in the dark – venture into this illuminating read to understand better how Google’s crawlers may navigate your site!





